
SRM Analysis Part 6
Retracing my steps
Since I don’t know where things are going wrong, I’m going back to everything I’ve done and making sure things are okay. The first thing I did was go through my R script to see if there was anything that was incorrectly assigning samples to data or eliminating them. I couldn’t find anything, so I started writing a new R script for an NMDS plot after averaging technical replciates. As I was writing this script, I found that my dataframe technicalReplicates were having sample names alternating between -1 and -2, instead of just -1. I went all the way back and found that my exported report from Skyline did not have samples O106-1 and O71-1!
I added in the RAW files for my missing replciates, files 10 and 28. These two samples didn’t have any missing data, so I’m not sure why they weren’t included in the first place! I also decied to readd the files that originally displayed no chromatograms just to see if there might have been an importing error: files 3, 16, 22 and 34. Files 3, 22 and 34 displayed data so I kept them, but 16 did not. I removed it and tried imorting it a third time. It still didn’t work, so I removed the file.
While I was in Skyline, I decided to check my PRTC peptides as well. I started by seeing what peaks were present in each PRTC peptide chromatogram. They all had one very clearly defined peak. The only peptide that did not have any peak picked was TASEFDSAIAQDK.



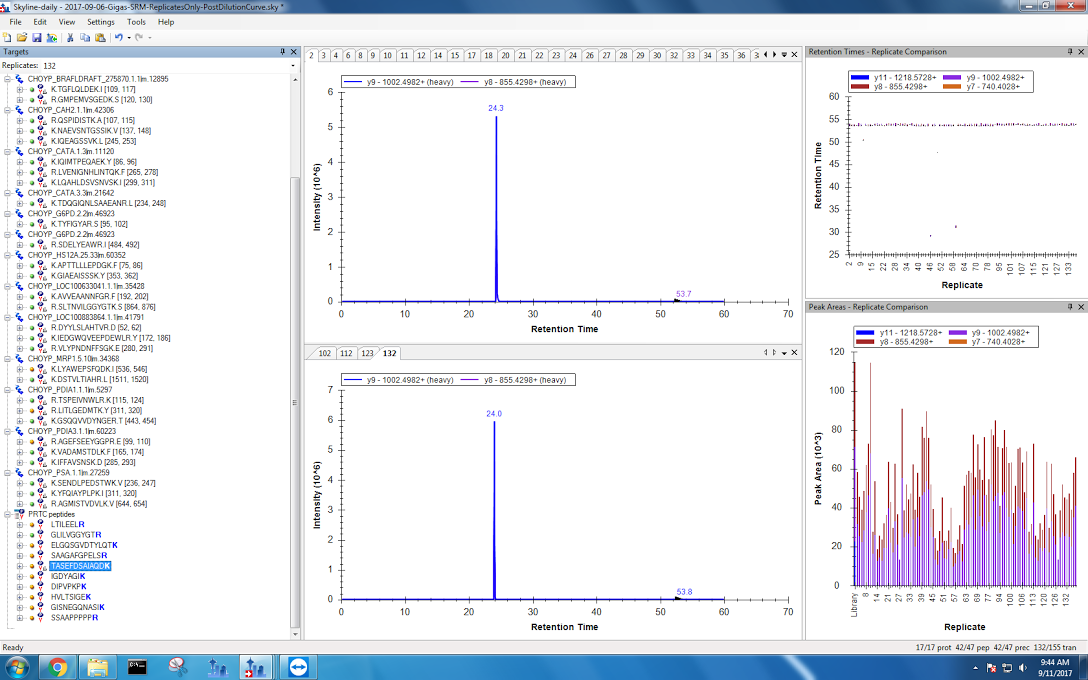





*Figures 1-9. Peaks present in PRTC peptides.
Using this document to predict retention times, I ensured that all of the proper peaks were picked.

Figure 10. Proper peak selected for PRTC peptide.
I then (accidentally) saved my revised Skyline file under the same name and overwrote the original file in OWL. The Skyline document can be found here.

*Figure 11. Export settings for revised data.
| I made sure the sequence file contained information for all of my samples, with the exception of O12 (one technical replicate is file 16, which has no data. I had to manually add the protein name CHOYP_ACAA2.1.1 | m.30666 to the file since that protein name was the only one that wasn’t exporting. Finally, I made sure I was missing no data when going through my R scripts. I resaved dataframes and images that were affected by the readdition of my samples. My NMDS clustering and ANOSIMs are still not producing anything desirable. I’m going to focus on making protein bar graphs for PCSGA instead. |
